|
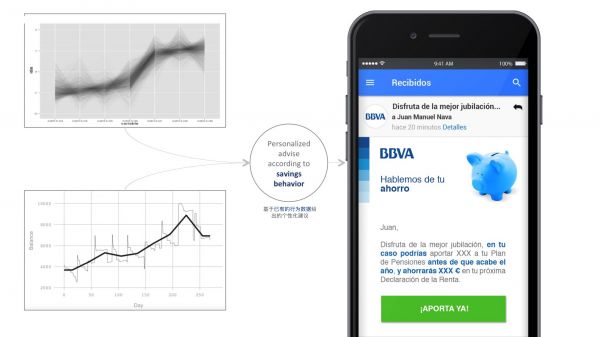
最后,像Spotify这样,依靠主观推荐的系统可以使用户对被推荐的内容拥有更多的主观性和多样性的选择。这种人为清理数据集或减小机器学习算法局限性的方法通常被称为“人类计算”或“交互式机器学习”或“相关反馈”。 为决策而设计 数据和算法也提供了个性化决策的手段。例如在D&A,我们开发了一套优秀的算法为BBVA客户提供财务建议。
例如,我们根据账户余额的时间演变来划分储蓄行为。通过这种技术,我们可以根据每个客户节省资金的能力来设计个性化投资机会。 这种决策性的算法对准确度有更高的要求,因为它们往往依赖于只能提供真实情况的数据集。在财务咨询的案例中,客户可以在不同银行操作多个账户,从而避免对储蓄行为的泄漏。目前来看这是一个比较好的设计实践,因为它可以让用户隐晦或明确地提供不良信息。数据学家的责任是明确反馈类型,从而丰富他们的模型,而设计师的工作是找到构成体验组成部分的方法。 为不确定性而设计 传统上讲,计算机程序的设计遵循的是二进制的逻辑,即通过将具有明确的、有限集合的、具体的和可预测的状态转换成工作流程来实现 。机器学习算法使用一种模糊逻辑来改变这种情况。它们的目的是寻找一组大概率接近样本行为规则的模式(参见Patrick Hebron的《为设计者的机器学习》一文中关于此定义的更加具体的介绍)。这种方法包含一定程度的不精确和不可预知的行为。它们经常会反馈一些关于已有信息精确度的提示。
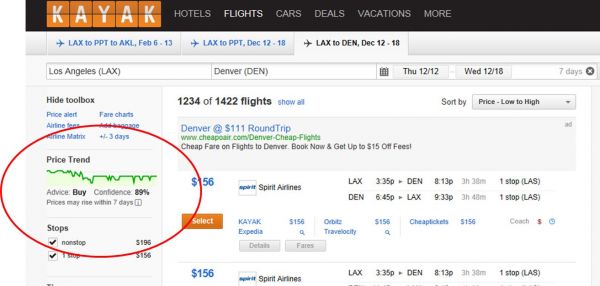
例如,预订平台Kayak通过分析历史价格变化来预测价格的演变。它的“预测”算法旨在让用户对是否在一个合适的时间购买一张票产生信心(参见Neal Lathia 《在票价背后的机器学习》)。数据学家自然倾向于给出算法预测值的精确度:“我们预测这个票价是x”。这个“预测”实际上是一个基于历史趋势的结果呈现。然而,预测与告知并不相同,设计师必须考虑这样的预测能够支撑用户的行为:“买!这个票价可能会增加”。“可能”与“价格走势的预测”是用户体验中的“完美衔接”,这个概念是由 Mark Weiser在施乐帕洛阿尔托研究中心工作期间首次提出,然后由 Chalmers and MacColl进一步将其发展为一个新的概念——seamful design(有缝设计): “Seamful design故意向用户展示“接缝”,并利用通常被认为是消极或有问题的特征”。 Seamful design 利用失败和局限来改善体验。它通过收集用户对于不良设计细节的建议来改善系统。DJ Patil描述了Data Jujitsu中的巧妙设计。
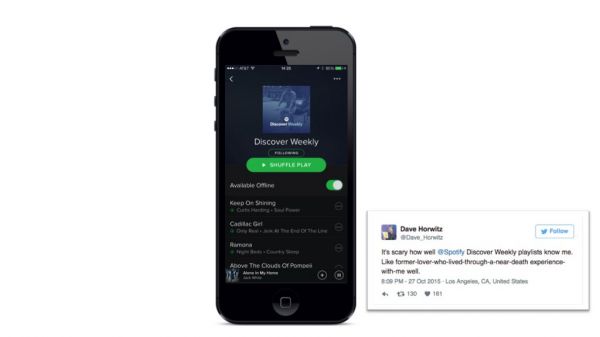
其他类型的机器学习算法运用精确度和召回率来处理接缝。 精确度评分体现了提供完全符合需求的结果的能力。(精确度指的是算法推送的内容与用户喜好的匹配程度) 召回率评分体现了提供大量可能的好建议的能力。(召回率指的是算法推送的内容与用户喜好匹配的内容的占比) 算法的理想之处在于提供高精确度和高召回率。不幸的是,精确度和召回率往往相互矛盾。在许多数据分析系统中,设计决策经常需要在精度与召回率之间进行折中选择。例如,在Spotify 的发现周刊中,必须根据推荐系统的性能来决定播放列表的大小。提供30首歌曲推荐的大播放列表可以凸显Spotify的信心,足够多的推荐歌曲增加了用户获取完美推荐的几率。 为参与而设计 今天,我们在网上阅读信息是基于自身行为和其他用户的行为产生的。算法通常会评估社交和新闻内容的相关性。这些算法的目的是通过推送内容获取更高的参与度或通过发送通知来建立用户阅读习惯。显然这些为我们所采取的行动并不一定是从我们自身利益出发。
在注意力经济中,设计师和数据学家都应该从用户的焦虑、强迫、恐惧、压力和其他精神负担中学习。资料来源:《地球村及其不适》。照片来源:Nicolas Nova (责任编辑:admin) |